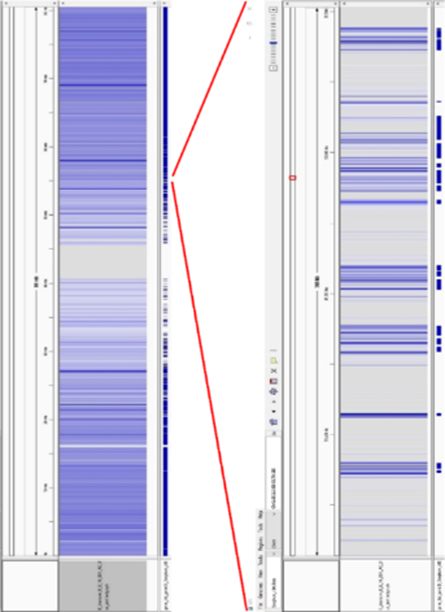
On the left of this image is the overview of chromosome 1 of sorghum.
1 of 3On the right is the zoom into a small segment of this chromosome.
2 of 3Lane 1 in both heat maps shows how many reads aligned to reference – the bluer of the colour the more of the reads are aligned. The light grey colour means no reads. Lane 2 in both heat maps shows the genic regions indicated by blue bars.
3 of 3